Variational autoencoders
Latent variable models form a rich class of probabilistic models that can infer hidden structure in the underlying data. In this post, we will study variational autoencoders, which are a powerful class of deep generative models with latent variables.
Representation
Consider a directed, latent variable model as shown below.
In the model above, and denote the latent and observed variables respectively. The joint distribution expressed by this model is given as
From a generative modeling perspective, this model describes a generative process for the observed data using the following procedure
If one adopts the belief that the latent variables somehow encode semantically meaningful information about , it is natural to view this generative process as first generating the “high-level” semantic information about first before fully generating . Such a perspective motivates generative models with rich latent variable structures such as hierarchical generative models —where information about is generated hierarchically—and temporal models such as the Hidden Markov Model—where temporally-related high-level information is generated first before constructing .
We now consider a family of distributions where describes a probability distribution over . Next, consider a family of conditional distributions where describes a conditional probability distribution over given . Then our hypothesis class of generative models is the set of all possible combinations
Given a dataset , we are interested in the following learning and inference tasks
- Selecting that “best” fits .
- Given a sample and a model , what is the posterior distribution over the latent variables ?
Learning Directed Latent Variable Models
One way to measure how closely fits the observed dataset is to measure the Kullback-Leibler (KL) divergence between the data distribution (which we denote as ) and the model’s marginal distribution . The distribution that ``best’’ fits the data is thus obtained by minimizing the KL divergence.
As we have seen previously, optimizing an empirical estimate of the KL divergence is equivalent to maximizing the marginal log-likelihood over
However, it turns out this problem is generally intractable for high-dimensional as it involves an integration (or sums in the case is discrete) over all the possible latent sources of variation . One option is to estimate the objective via Monte Carlo. For any given datapoint , we can obtain the following estimate for its marginal log-likelihood
In practice however, optimizing the above estimate suffers from high variance in gradient estimates.
Rather than maximizing the log-likelihood directly, an alternate is to instead construct a lower bound that is more amenable to optimization. To do so, we note that evaluating the marginal likelihood is at least as difficult as as evaluating the posterior for any latent vector since by definition .
Next, we introduce a variational family of distributions that approximate the true, but intractable posterior . Further henceforth, we will assume a parameteric setting where any distribution in the model family is specified via a set of parameters and distributions in the variational family are specified via a set of parameters .
Given and , we note that the following relationships hold true1 for any and all variational distributions
where we have used Jensen’s inequality in the final step. The Evidence Lower Bound or ELBO in short admits a tractable unbiased Monte Carlo estimator
so long as it is easy to sample from and evaluate densities for .
Which variational distribution should we pick? Even though the above derivation holds for any choice of variational parameters , the tightness of the lower bound depends on the specific choice of .
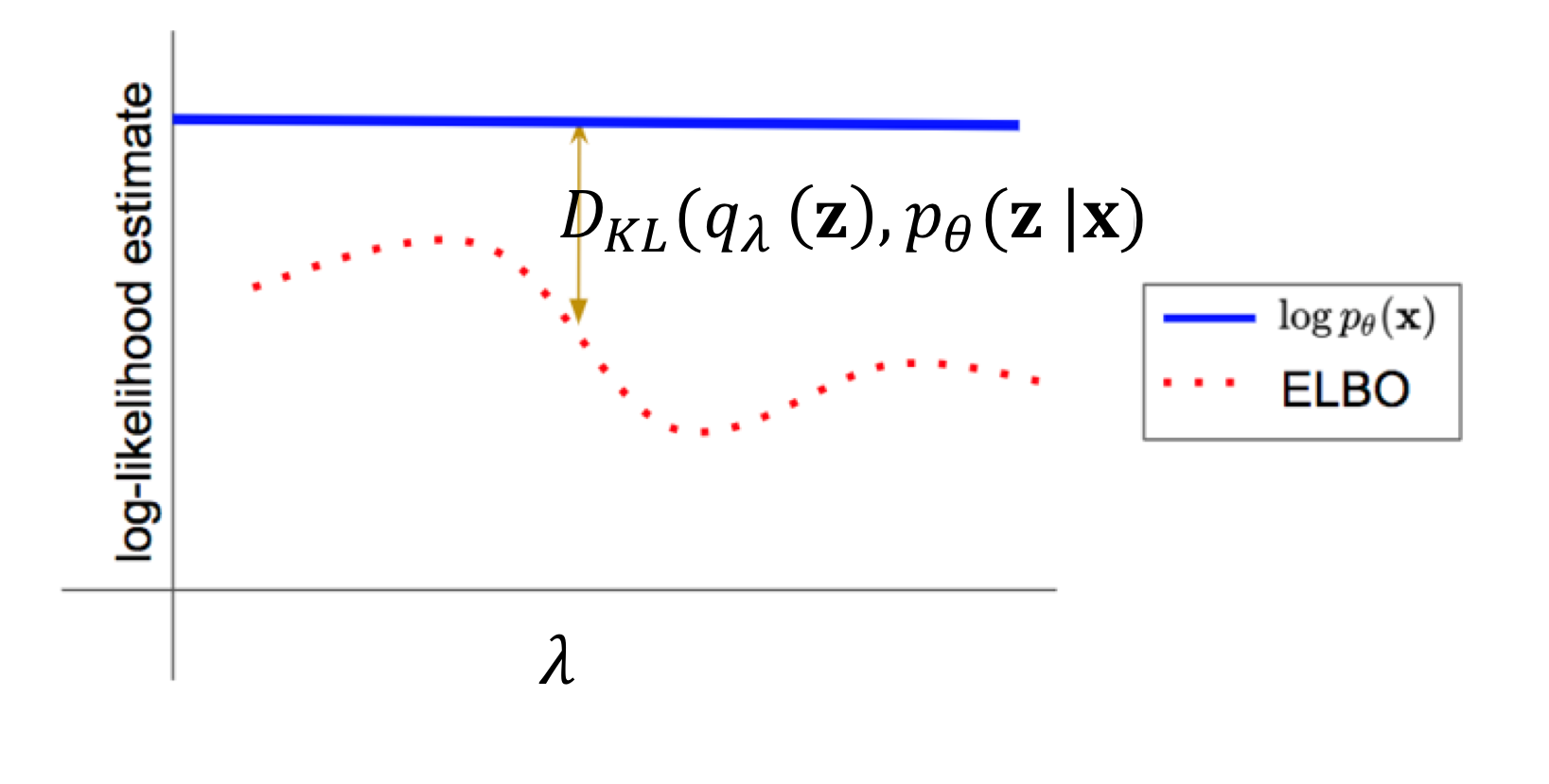
In particular, the gap between the original objective(marginal log-likelihood ) and the ELBO equals the KL divergence between the approximate posterior and the true posterior . The gap is zero when the variational distribution exactly matches .
In summary, we can learn a latent variable model by maximizing the ELBO with respect to both the model parameters and the variational parameters for any given datapoint
Black-Box Variational Inference
In this post, we shall focus on first-order stochastic gradient methods for optimizing the ELBO. These optimization techniques are desirable in that they allow us to sub-sample the dataset during optimization—but require our objective function to be differentiable with respect to the optimization variables. This inspires Black-Box Variational Inference (BBVI), a general-purpose Expectation-Maximization-like algorithm for variational learning of latent variable models, where, for each mini-batch , the following two steps are performed.
Step 1
We first do per-sample optimization of by iteratively applying the update
where , and denotes an unbiased estimate of the ELBO gradient. This step seeks to approximate the log-likelihood .
Step 2
We then perform a single update step based on the mini-batch
which corresponds to the step that hopefully moves closer to .
Gradient Estimation
The gradients and can be estimated via Monte Carlo sampling. While it is straightforward to construct an unbiased estimate of by simply pushing through the expectation operator, the same cannot be said for . Instead, we see that
This equality follows from the log-derivative trick (also commonly referred to as the REINFORCE trick). The full derivation involves some simple algebraic manipulations and is left as an exercise for the reader. The gradient estimator is thus
However, it is often noted that this estimator suffers from high variance. One of the key contributions of the variational autoencoder paper is the reparameterization trick, which introduces a fixed, auxiliary distribution and a differentiable function such that the procedure
is equivalent to sampling from . By the Law of the Unconscious Statistician, we can see that
In contrast to the REINFORCE trick, the reparameterization trick is often noted empirically to have lower variance and thus results in more stable training.
Parameterizing Distributions via Deep Neural Networks
So far, we have described and in the abstract. To instantiate these objects, we consider choices of parametric distributions for , , and . A popular choice for is the unit Gaussian
in which case is simply the empty set since the prior is a fixed distribution. Another alternative often used in practice is a mixture of Gaussians with trainable mean and covariance parameters.
The conditional distribution is where we introduce a deep neural network. We note that a conditional distribution can be constructed by defining a distribution family (parameterized by ) in the target space (i.e. defines an unconditional distribution over ) and a mapping function . In other words, defines the conditional distribution
The function is also referred to as the decoding distribution since it maps a latent code to the parameters of a distribution over observed variables . In practice, it is typical to specify as a deep neural network.
In the case where is a Gaussian distribution, we can thus represent it as
where and are neural networks that specify the mean and covariance matrix for the Gaussian distribution over when conditioned on .
Finally, the variational family for the proposal distribution needs to be chosen judiciously so that the reparameterization trick is possible. Many continuous distributions in the location-scale family can be reparameterized. In practice, a popular choice is again the Gaussian distribution, where
where is the Cholesky decomposition of . For simplicity, practitioners often restrict to be a diagonal matrix (which restricts the distribution family to that of factorized Gaussians).
Amortized Variational Inference
A noticable limitation of black-box variational inference is that Step 1 executes an optimization subroutine that is computationally expensive. Recall that the goal of the Step 1 is to find
For a given choice of , there is a well-defined mapping from . A key realization is that this mapping can be learned. In particular, one can train an encoding function (parameterized by ) (where is the space of parameters) on the following objective
It is worth noting at this point that can be interpreted as defining the conditional distribution . With a slight abuse of notation, we define
and rewrite the optimization problem as
It is also worth noting that optimizing over the entire dataset as a subroutine everytime we sample a new mini-batch is clearly not reasonable. However, if we believe that is capable of quickly adapting to a close-enough approximation of given the current choice of , then we can interleave the optimization and . The yields the following procedure, where for each mini-batch , we perform the following two updates jointly
rather than running BBVI’s Step 1 as a subroutine. By leveraging the learnability of , this optimization procedure amortizes the cost of variational inference. If one further chooses to define as a neural network, the result is the variational autoencoder.
Footnotes
-
The first equality only holds if the support of includes that of . If not, it is an inequality. ↩