Generative adversarial networks
We now move onto another family of generative models called generative adversarial networks (GANs). GANs are unique from all the other model families that we have seen so far, such as autoregressive models, VAEs, and normalizing flow models, because we do not train them using maximum likelihood.
Likelihood-free learning
Why not? In fact, it is not so clear that better likelihood numbers necessarily correspond to higher sample quality. We know that the optimal generative model will give us the best sample quality and highest test log-likelihood. However, models with high test log-likelihoods can still yield poor samples, and vice versa. To see why, consider pathological cases in which our model is comprised almost entirely of noise, or our model simply memorizes the training set. Therefore, we turn to likelihood-free training with the hope that optimizing a different objective will allow us to disentangle our desiderata of obtaining high likelihoods as well as high-quality samples.
Recall that maximum likelihood required us to evaluate the likelihood of the data under our model . A natural way to set up a likelihood-free objective is to consider the two-sample test, a statistical test that determines whether or not a finite set of samples from two distributions are from the same distribution using only samples from and . Concretely, given and , we compute a test statistic according to the difference in and that, when less than a threshold , accepts the null hypothesis that .
Analogously, we have in our generative modeling setup access to our training set and . The key idea is to train the model to minimize a two-sample test objective between and . But this objective becomes extremely difficult to work with in high dimensions, so we choose to optimize a surrogate objective that instead maximizes some distance between and .
GAN Objective
We thus arrive at the generative adversarial network formulation. There are two components in a GAN: (1) a generator and (2) a discriminator. The generator is a directed latent variable model that deterministically generates samples from , and the discriminator is a function whose job is to distinguish samples from the real dataset and the generator. The image below is a graphical model of and . denotes samples (either from data or generator), denotes our noise vector, and denotes the discriminator’s prediction about .
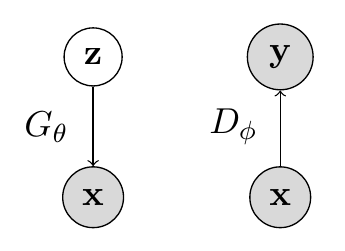
The generator and discriminator both play a two player minimax game, where the generator minimizes a two-sample test objective () and the discriminator maximizes the objective (). Intuitively, the generator tries to fool the discriminator to the best of its ability by generating samples that look indisginguishable from .
Formally, the GAN objective can be written as:
Let’s unpack this expression. We know that the discriminator is maximizing this function with respect to its parameters , where given a fixed generator it is performing binary classification: it assigns probability 1 to data points from the training set , and assigns probability 0 to generated samples . In this setup, the optimal discriminator is:
On the other hand, the generator minimizes this objective for a fixed discriminator . And after performing some algebra, plugging in the optimal discriminator into the overall objective gives us:
The term is the Jenson-Shannon Divergence, which is also known as the symmetric form of the KL divergence:
The JSD satisfies all properties of the KL, and has the additional perk that . With this distance metric, the optimal generator for the GAN objective becomces , and the optimal objective value that we can achieve with optimal generators and discriminators and is .
GAN training algorithm
Thus, the way in which we train a GAN is as follows:
For epochs do:
- Sample minibatch of size from data:
- Sample minibatch of size of noise:
- Take a gradient descent step on the generator parameters :
- Take a gradient ascent step on the discriminator parameters :
Challenges
Although GANs have been successfully applied to several domains and tasks, working with them in practice is challenging because of their: (1) unstable optimization procedure, (2) potential for mode collapse, (3) difficulty in evaluation.
During optimization, the generator and discriminator loss often continue to oscillate without converging to a clear stopping point. Due to the lack of a robust stopping criteria, it is difficult to know when exactly the GAN has finished training. Additionally, the generator of a GAN can often get stuck producing one of a few types of samples over and over again (mode collapse). Most fixes to these challenges are empirically driven, and there has been a significant amount of work put into developing new architectures, regularization schemes, and noise perturbations in an attempt to circumvent these issues. Soumith Chintala has a nice link outlining various tricks of the trade to stabilize GAN training.
Selected GANs
Next, we focus our attention to a few select types of GAN architectures and explore them in more detail.
f-GAN
The f-GAN optimizes the variant of the two-sample test objective that we have discussed so far, but using a very general notion of distance: the . Given two densities and , the -divergence can be written as:
where is any convex1, lower-semicontinuous2 function with . Several of the distance “metrics” that we have seen so far fall under the class of f-divergences, such as KL, Jenson-Shannon, and total variation.
To set up the f-GAN objective, we borrow two commonly used tools from convex optimization3: the Fenchel conjugate and duality. Specifically, we obtain a lower bound to any f-divergence via its Fenchel conjugate:
Therefore we can choose any f-divergence that we desire, let and , parameterize by and by , and obtain the following fGAN objective:
Intuitively, we can think about this objective as the generator trying to minimize the divergence estimate, while the discriminator tries to tighten the lower bound.
BiGAN
We won’t worry too much about the BiGAN in these notes. However, we can think about this model as one that allows us to infer latent representations even within a GAN framework.
CycleGAN
CycleGAN is a type of GAN that allows us to do unsupervised image-to-image translation, from two domains .
Specifically, we learn two conditional generative models: and . There is a discriminator associated with that compares the true with the generated samples . Similarly, there is another discriminator associated with that compares the true with the generated samples . The figure below illustrates the CycleGAN setup:
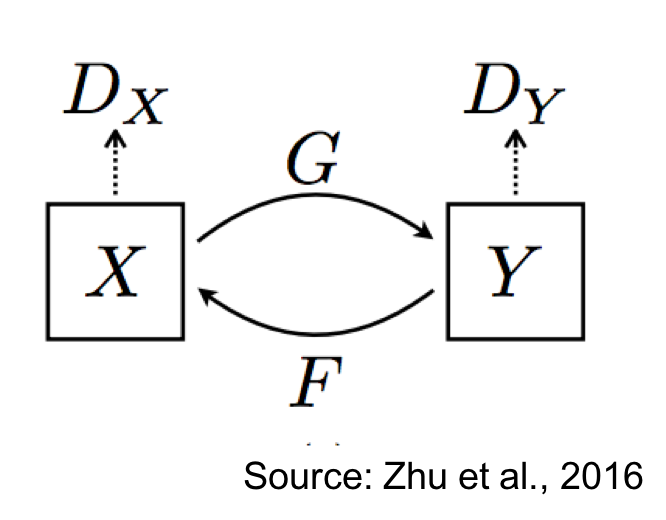
CycleGAN enforces a property known as cycle consistency, which states that if we can go from to via , then we should also be able to go from to via . The overall loss function can be written as: